Give your kids futuristic names with a neural network!

We live in the future. Computers drive cars, fight parking tickets and raise children. Why not let machines name our children, too? What if a computer program could find the ideal baby name. Maybe it’s a perfect combination of both parents’ names—or maybe it’s a name that’s completely unique.
I trained a neural network on a list of 7500 popular American baby names, forcing it to turn each name into a mathematical representation called an embedding. Once I had a model that could translate between names and their embeddings, I could generate new names, blend existing names together, do arithmetic on names, and more.
Embeddings
Embeddings are an important machine learning technique. Facial-recognition algorithms are trained to convert images of faces into face embeddings—sequences of say, 16 numbers, which can be compared to find similar faces. Word-embedding networks turn words into vectors of numbers whose values map to their semantic meaning in interesting ways.
I trained an algorithm to generate name embeddings for the 7500 common baby names using a neural network called an autoencoder—a neural network trained to reconstruct its input after the data has been squeezed through a bottleneck (called a latent vector) that allows a limited amount of data through. The bottleneck forces the network to learn only the most important features of a name, compressing it by stripping superfluous information.
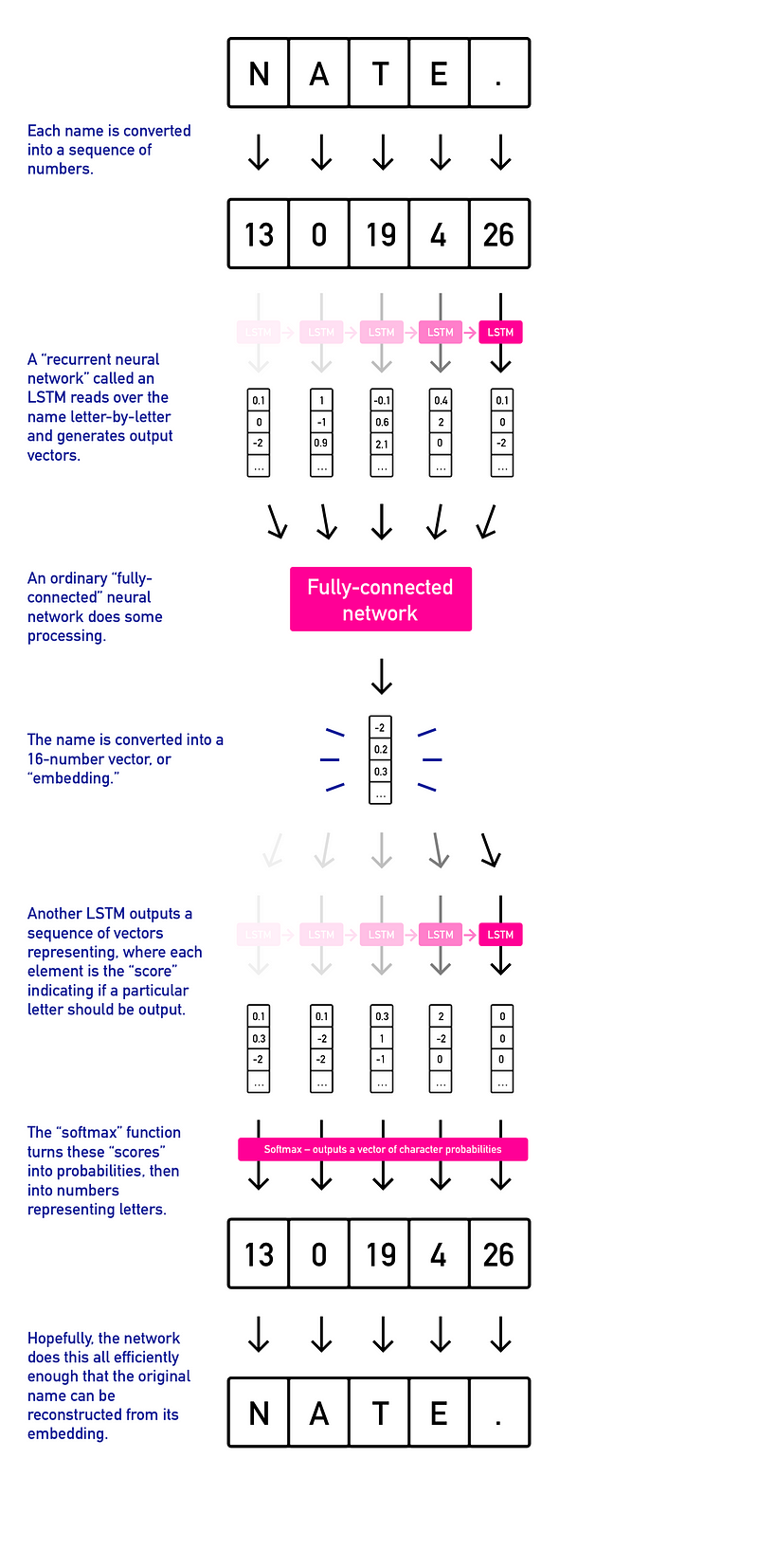
My network took 10-character names as input (shorter names were padded with a special <NULL> character), ran an LSTM over them, and generated a vector of 64 floating-point numbers that roughly fit a gaussian distribution. It took this embedding vector and attempted to reconstruct the input name’s characters.

The model took around a 30 minutes running on a GPU to train to a reasonable level of accuracy — as it trains, you can see the model slowly getting better at modeling and reconstructing names:
Playing with embeddings: doing math
Once we’ve converted words into vectors, we can add, subtract and multiply them. I’ve noticed a few interesting properties:
When names differ by a simple feature (like an extra “a”, you can subtract out that feature and add it onto other names:

It doesn’t always work, though:

You can “multiply” names by constants, which has some strange effects:

Blending names— for couples who can’t pick just one!
If you can do simple arithmetic on names, you can also linearly blend them, taking a weighted sum of two name embeddings and generating intermediate names from those

Generating random names
I built the embedding network as a variational autoencoder—a network that encourages the embeddings to have a normal distribution, rather than whatever crazy unpredictable distribution just happens to work best. This means it should be possible to randomly sample from a gaussian distribution to generate random embeddings that should yield plausible names:

Some of them definitely don’t make much sense (“P” or “Hhrsrrrrr”) but I kind of like a couple (“Pruliaa?” “Halden?” “Aradey?”)
If this post gets 1,000 stars, I will name my first-born child using this code. Please like and share!
💻 Check out the code!
🌟 I’ve been writing about my other adventures in deep learning here~